


Everhour é um sistema para registro de atividades popular adotado por empresas de todos os portes. Na EximiaCo, utilizamos o Everhour para registrar nossos engajamentos com nossos clientes.
O Everhour oferece uma API fácil de usar, baseada em HTTP.
Para obter a chave de acesso para a API do Everhour, você deve seguir os seguintes passos:
Lembre-se de manter sua chave de API segura e não compartilhá-la publicamente, pois ela dá acesso aos dados da sua conta no Everhour.
Seu usuário precisa ter acesso administrativo para poder obter esse acesso.
Para fazer uso da API, usaremos o pacote requests. Para poder tratar os dados, usaremos o pandas.
! pip install pandas requestsNo código, é importante importar esses dois pacotes.
import pandas as pd
import requestsVamos então iniciar nossa cruzada por obtenção de dados do Everhour. Para começar, vamos escrever código genérico para interagir com endpoints chaves.
def fetch_everhour(api_token, entity, params = {}):
url = f"https://api.everhour.com/team/{entity}"
headers = {
'Content-Type': 'application/json',
'X-Api-Key': api_token
}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
return response.json()
else:
print (response)
return NoneVocê pode aprender um bocado sobre os endpoints do Everhour na documentação oficial.
def convert_to_dataframe(source):
if source:
df = pd.DataFrame(source)
return df
else:
return pd.DataFrame() Por exemplo, o código abaixo resgata todas os usuários definidas no Everhour da organização.
api_token = "SEU-API-TOKEN"
users = convert_to_dataframe(fetch_everhour(api_token, "users"))
users.head()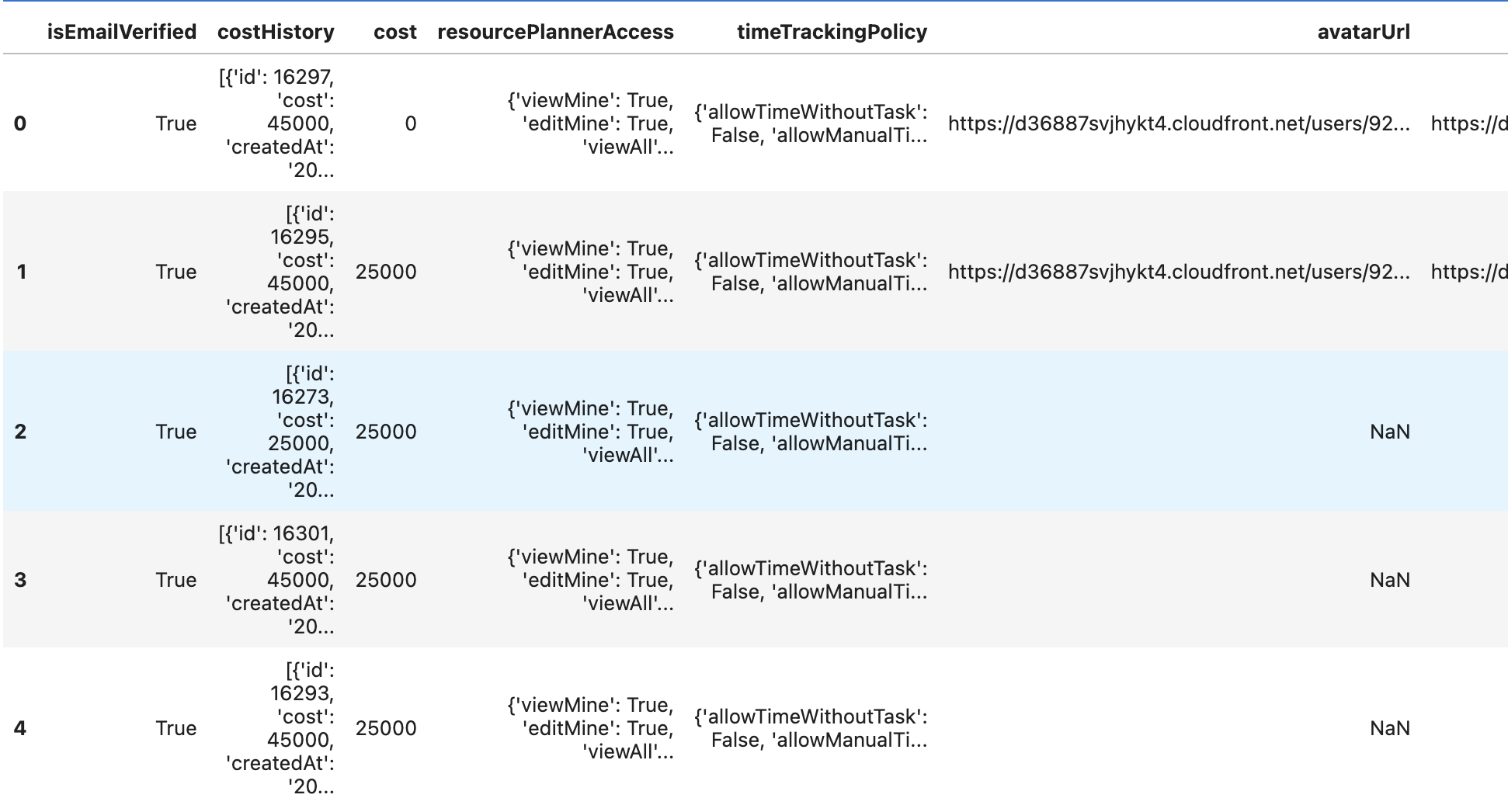
Felizmente, Pandas ajuda na hora de entender quais são os dados que foram retornados.
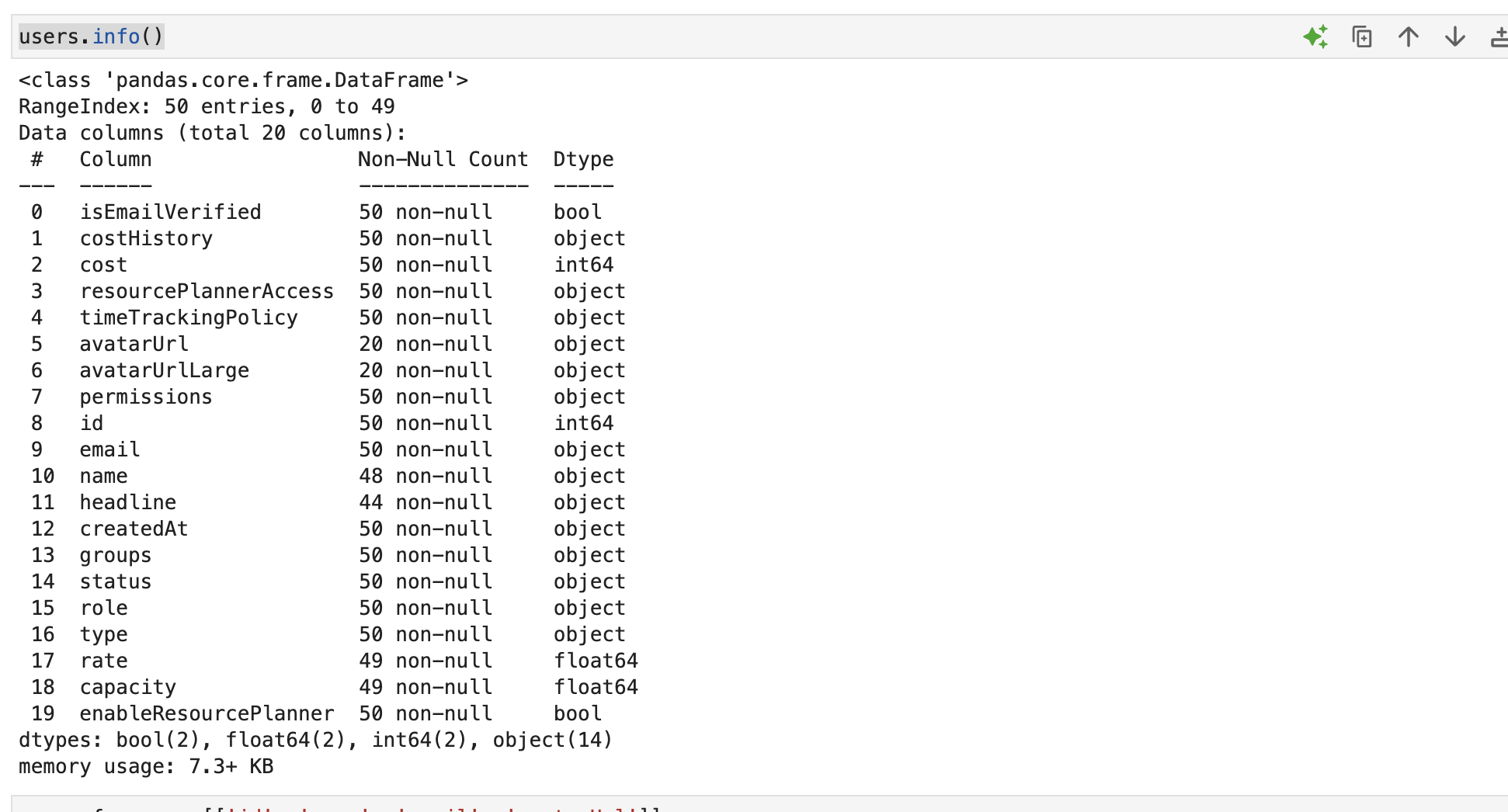
Com os dados obtidos, interessante resgatar apenas informações mais interessantes.
users_f = users[['id', 'name', 'email']]
users_fAgora que conhecemos os usuários, podemos obter também dados relacionados aos apontamentos que já foram realizados.
params = {
"from": "2024-04-01",
"to": "2024-04-16",
"limit": 10000,
"page": 1
}
times = convert_to_dataframe(fetch_everhour(api_token, "time", params))Aqui é interessante observar a possibilidade de passar informações de intervalo.
Novamente, o Everhour fornece provavelmente mais informações do que necessitamos.
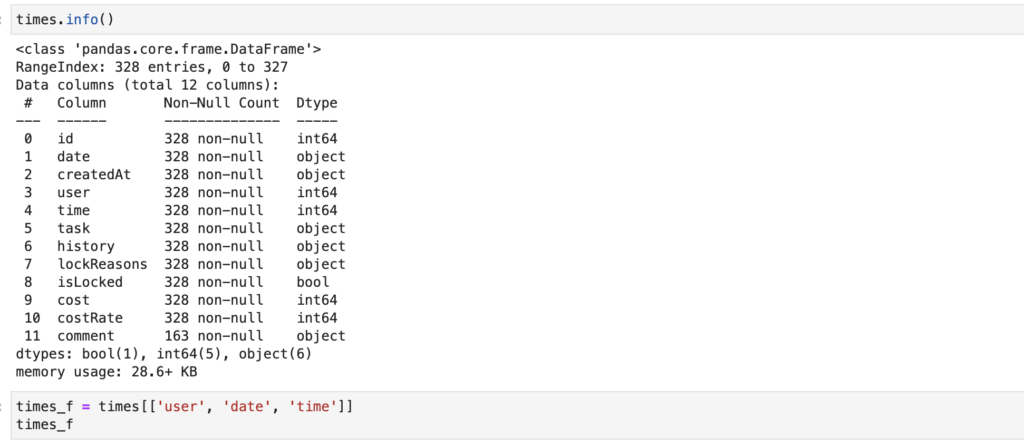
times_f = times[['user', 'date', 'time']]
times_fO campo “user” possui um id.
De um lado, temos dia e volume de horas lançados. De outro, temos os dados dos usuários (pessoas que apontam horas). Vamos consolidar os dados em uma consulta só.
data = pd.merge(times_f, users_f, left_on="user", right_on="id", how="left")
summary = data[['name', 'time']]
summary.groupby("name").sum().plot(kind="bar")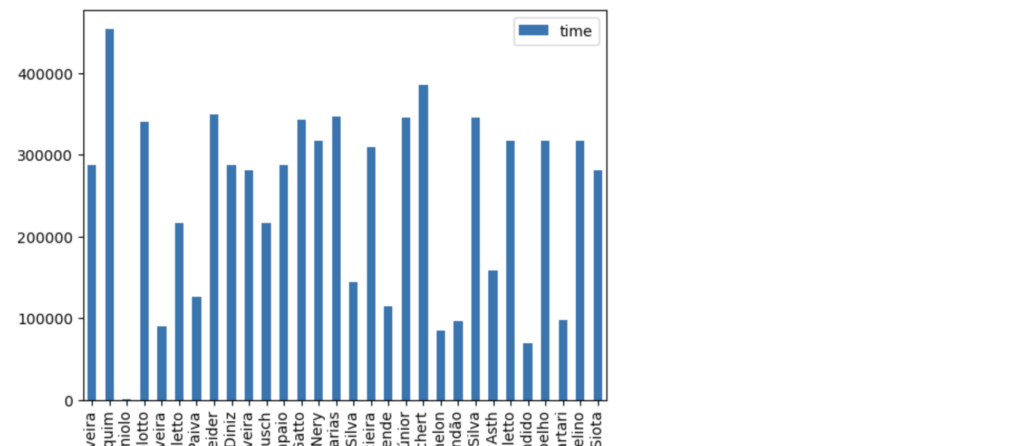
Bacana, não?
No lugar de passar tanto trabalho com tantos dados, podemos criar uma classe que acelera o processo como um todo.
import requests
import pandas as pd
class EverhourClient:
def __init__(self, api_token):
self.api_token = api_token
self.base_url = "https://api.everhour.com/team/"
def fetch_everhour(self, entity, params={}):
url = f"{self.base_url}{entity}"
headers = {
'Content-Type': 'application/json',
'X-Api-Key': self.api_token
}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
return response.json()
else:
print(response)
return None
def convert_to_dataframe(self, source):
if source:
return pd.DataFrame(source)
else:
return pd.DataFrame()
def get_all_users(self):
users_json = self.fetch_everhour("users")
users_df = self.convert_to_dataframe(users_json)
return users_df[['id', 'name', 'email']]
def get_appointments(self, start, end):
params = {
"from": start,
"to": end,
"limit": 10000,
"page": 1
}
times_json = self.fetch_everhour("time", params)
times_df = self.convert_to_dataframe(times_json)
return times_df[['id', 'user', 'date', 'time']]
def get_summary(self, start, end):
times_df = self.get_appointments(start, end)
users_df = self.get_all_users()
data = pd.merge(times_df, users_df, left_on="user", right_on="id", how="left")
summary = data[['name', 'time']]
return summary.groupby("name").sum()Esse código torna a utilização da API algo muito mais fácil.
api_token = "SEU-API-TOKEN"
client = EverhourClient(api_token)
# Get all users
users = client.get_all_users()
print(users.head())
# Get appointments between dates
appointments = client.get_appointments("2024-04-01", "2024-04-16")
print(appointments.head())
# Get time summary between dates
summary = client.get_summary("2024-04-01", "2024-04-16")
print(summary)